
Mike Sosteric
Department of Global and Social Analysis
Athabasca University
mikes@athabascau.ca
Note: The current version of the macros introduced here is always available at http://www.icaap.org/software
As editors and their assistants are well aware, even the creation of an electronic journal requires work. From editorial intake, peer review, to markup and final production, there are many steps involved in the creation of professional content on the web, and many issues that must be considered. Some of these tasks are professional and academic and some are technical and creative. However some tasks are simply downright tedious. This is certainly true of final journal production where a peer reviewed and copy edited manuscript is submitted for final HTML or SGML production.
As anyone who has ever created HTML pages is aware, converting basic text to HTML markup can be tedious, time consuming, and error prone. Not only do paragraphs have to be marked, but special formatting instructions which identify emphasised text (e.g., italics, bold underline), and special “entities” which identify special characters (e.g., “&” for the “&” character, or “&lsquo” for a left single quote “ ‘ “ must be inserted to ensure document portability from one system to the another. It is probably not unreasonable to suggest that a complex journal article with a significant amount of formatting and special characters would take several hours to translate into HTML - if markup was conducted manually.
Of course, in recent years various HTML editors have appeared that assist with document markup1. Some of these editors are simple text editors and provide basic assistance in the markup of text. Generally, these editors will provide shortcut commands for the insertion of basic HTML tags. They may also provide pop-up assistance to help authors remember various elements and attributes of the SGML system they are working with. These basic text editors are certainly an improvement over unassisted hand markup, but they do not significantly reduce the amount of time that editorial assistants must spend marking up a journal article. That is, basic HTML aware text editors do not provide significant document automation and are generally dependent on human intervention for all markup decisions.
There are other solutions. For example, most word-processors like Microsoft Word, now come with options to save documents as HTML. At first glance this provides and easy solution to the problem of tedious document markup. To the untrained eye, it appears that the word-processor is able to adequately and seamlessly convert the document into a properly formatted HTML equivalent. Taking this approach introduces a high degree of automation into document creation. However there is a significant downside. Generally, this sort of automated conversion takes many liberties with the output document. In order to achieve special effects, or in order to reproduce the appearance of a word-processor page, word-processors and other automated document packages often insert all manner of unwanted markup, use questionable HTML “tricks,” make poor decisions when it comes to document formatting, and otherwise create a hidden and unstructured mess of the underlying HTML. This “messy” html makes document maintenance difficult and increases the likelihood that your HTML pages will, because of the liberties taken with HTML code, “break” a client browser or future conversion process.
This is not to suggest that these tools do not have their place. As tools for the creation of general web pages, or the top level pages of scholarly journals (home pages, etc.), they can be invaluable time-savers. However, when documents are journal articles, and where the primary concerns revolve around portability (documents load in all browsers) and permanence (documents will always be understandable by software) quick conversion of this nature should be eschewed.
This reason for this is plain. The only way to achieve long term availability of electronic documents is to ensure documents adhere strictly to SGML standards. The details of SGML systems are beyond the scope of this work. But suffice it to note that when documents are well structured and follow “legal” SGML form, then the longevity of the document is enhanced. For example, if, as a journal editor, you place all your articles online in a messy HTML format, and in 5 years HTML passes away as the standard markup language, you will be faced with an extremely difficult and labour intensive conversion process. The lack of adherence to standards, lack of structure, etc., will make conversion of your documents to new formats very difficult to automate with conversion filters. It will simply be impossible to program into the filters the ability to handle all the possibilities. In short, you will have failed in the principle task of ensuring document permanence. However, if you have kept your documents relatively clean and well structured, and followed a documented and tightly controlled SGML implementation, then conversion becomes much easier. While there will still be significant labour costs involved in moving to new formats, it will not be of the same order as converting from scratch a set of poorly structured and inconsistently tagged journal articles.
The need to consider the longevity of your documents, and the lack of control and standardisation evident in many automation tools, creates a significant dilemma - increase short term production costs to enhance long term document permanence by requiring hand markup and a tedious standardisation process. Or, save in the short term by using cheap and readily available word-processor or HTML WYSIWYG packages, but sacrifice the long term availability of your journal articles. This is not a pleasant choice.
There is, however, another route. Although at first glance difficulty and cost appear to prohibit its adoption. This route involves both the creation of a standardised journal markup structure utilising SGML (Standard Generalised Markup Language)2 and the full exploitation of available technologies to automate the journal production process. This is the approach taken by major publishing houses and for good reason. Creating an SGML system to represent journal articles has many benefits that cannot be realised with simple HTML. It creates a standard and well documented markup system which can be applied consistently across all the journals of a given publisher, it significantly eases production since automation of document conversion is much easier when all documents conform to a strict logical structure, it guarantees long term document availability regardless of the current flavour of the month markup language, and it allows for the creation of multiple versions of a document from a single SGML source file. However the high startup cost, the high cost of some SGML toolsets, and the very steep learning curve, prohibits individual journal editors from taking this approach.
This is unfortunate since the application of solutions based on SGML will eventually be an expected part of journal production. Libraries will certainly expect that the titles they subscribe to have taken steps to ensure long term availability. However universities and authors will also eventually catch on to the importance of a system based on SGML. Unfortunately, if the entrance barriers to SGML systems remain high, only major commercial publishers will be able to afford to adopt this solution. This will hamstring independent publication in obvious ways and ensure the continued domination of commercial interests in a non-competitive environment.
Fortunately, these barriers are not necessarily prohibitive if economies of scale are created (i.e., if a central organisation develops an SGML application appropriate for journal article production) and if technologies are exploited to automate as much as possible the steps in the production process. The creation of a simple, but comprehensive and freely available, industry standard Document Type Definition (DTD)3 for journal articles would significantly enhance the prestige and technical sophistication of independent efforts. Although ICAAP is currently developing such a DTD4, full treatment of this initiative is beyond the scope of this short technical article. Our primary concern here is the exploitation of technology to automate the production process and ease the task of final journal production.
As noted above, current automation systems based on default word-processor conversion to HTML creates significant problems. However word-processor macro5 utilities can be utilised to overcome these limitations. Macros can be custom tailored to automated the most tedious tasks of journal markup. They can also allow for human intervention and decision making at the most critical steps in the conversion process. In addition, macros can be customised to conform to industry standard SGML DTDs. In order to demonstrate the potential of macros to automate common production tasks, and thereby lower the cost of production, ICAAP has created a freely available set of macros for Microsoft Word 97 and latter versions that provides automation routines for a significant part of the final journal markup. In addition, these macros are designed to move journal production towards a more standardised markup system based on the ICAAP IXML DTD6. Tasks automated include document cleaning and normalisation, the conversion of italicised text to plain text wrapped in <I>...</I> containers, the conversion of quotations and a limited set of special characters to their ISO entity equivalents. Other macros are available including an experimental macro which converts footnotes and endnotes to a form suitable for HTML markup.
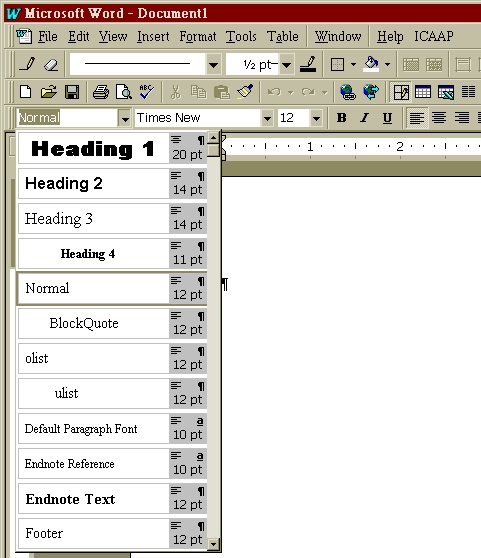
Note however that not all tasks of article markup can be fully automated. Some tasks, like the application of headings (e.g., <H1>), paragraphs and block-quotations generally do not automate well. The reason for the inability to fully automate these tasks is simple. Full automation would require the consistent application of document styles to authored documents. Styles are the user defined “templates” which can be applied to various sections of text in order to create formatting. Consistent application of styles ensures that computer programs can consistently identify structures like headings, paragraphs and quotations. Consider this document, for example. All paragraphs are “styled” using the normal style. If you are reading this document in its original Microsoft Word format, you would see the word “normal” in the style box at the top of the word-processor window. By the same token, all headings are supplied with a “heading” style. If you pass your cursor over the following heading, you will see the “Normal” keyword change to “Heading 4”.
Unfortunately, there are no accepted standard ways of applying formatting and styling to paragraph and heading structures. This is because it is possible to name styles whatever you wish. For example, this document's original Microsoft Word stylesheet uses “Normal,” “Heading 1,” “Heading 2,” etc. to mark the appropriate document structures. However there is no guarantee that another author will use the same styles, or the same names.
This unstandardised use of styles is a significant obstacle to full automation of document production. For example, while it is possible to fully automate the markup of this document because it is possible to predict how each structure is named (paragraphs are identified by a “normal” style, headings by “Heading 1”, etc.), another document may not have the same style names. To use the automation routines in this document on another document without the exact same styles would fail. As a result of this, it is generally difficult to consistently map paragraph structures to their corresponding ICAAP or HTML representations. This is not to say that it is impossible. This macro package comes with a macro entitled HTMLcontainText that will correctly identify paragraphs and headers from levels 1 to 4 without human intervention. However this macro depends on authors using the same style names as exist in this document. If authors use a different name to style their paragraph (e.g., “paragraph text”) or if they change the name of the ICAAP styles provided with the macros, then automation will fail.
In this case it is possible to fall back on partial automation of the process. The ICAAP package included with this article comes with a set of macros that will add, for example, a <P> . </P> container provided the user first positions the cursor at the start of a new paragraph. Similar macros are also provided for <BLOCKQUOTE> and header levels 1 to 4. To invoke, simply place the cursor at the start of the paragraph and press CTL P (control P), CONTROL Q, or CONTROL [1 to 4] for the corresponding ICAAP elements. This is not an ideal solution to be sure. But a quick test run will convince the reader of the utility of even this semi-automated process.
To use the macros, simply download the automation.zip file, unzip the file icaap.dot and place it in your word-processors template directory. On my computer, the template directory is c:\microsoft office\templates. Then, open a document for conversion and “attach” the ICAAP document template (DOT) file. To attach the file go to the “ tools/Templates and Add Ins” menu and select attach from the list of options that appear. An attachment menu should appear. Select ICAAP.DOT from the list of files. If you have successfully attached the template, an ICAAP menu will appear at the top of your word-processor window indicating that the macros are available for use. Shortcut keys for <P>, <BLOCKQUOTE> and heading levels will also be mapped. If you are concerned about the modification to your interface, don't worry. When you close the document your original key bindings will be restored and the ICAAP menu will disappear.
A glance at the ICAAP menu will reveal two basic categories of Macros. There are the semi- automated macros on the main menu like <P> which require some user intervention, and the fully automated macros which handle their tasks without intervention. The fully automated macros are under the automation sub menu.
Because the automated macros convert special characters, you should always run the automated functions first. For example, in HTML files, the less than character “<“ is disallowed because it identifies the start of an HTML tag. If you want such a character to actually appear in your document, then you must replace the less than character with the character entity “<” The automated macros provided in this package will change these for you. However, if you have already converted your paragraphs and heading, then the <P> tags will be converted to “<P>”. This is probably not what you wanted to accomplish.
To run the automated macros you have two choices. On the “automation” sub menu the top most macro is entitled “Run all Macros.” This macro runs, in the appropriate sequence, the standard suite of ICAAP macros (the standard macros are identified with a “*” on the “automation” sub menu). The macro sequence is as follows.
In some cases, authors may submit poorly structured documents that may interfere with the automatic execution of the macros. In this case, try running each of these macros individually. But be careful about the order in which you run the macros. The macro ConvertSpecialCharacters should be run before any HTML markup is applied to the text. The ConverSpecialCharacters macro can, however, be run after document cleaning and the conversion of quotations. In general it is best to run the macros in the order they appear on the menu. Don't be afraid to experiment. But be sure to save copies of all critical documents before such experimentation.
Additional macros are provided if needed. These include:
In addition to the fully automated tasks, the macro package provides semi-automated macros (like <P>) for those situations where document authors did not apply ICAAP styles. To use these macros, simply position the cursor at the beginning of the text structure, and press the appropriate control key combination (CONTROL P for <P>) and the macro will mark the paragraph, and move to the next paragraph position. At this point you shouldn't need to reposition the cursor since the macro will have positioned the cursor correctly in most cases. Simply re-invoke the appropriate macro to tag the next text structure.
As noted above, converting journal articles to a reasonably clean and standardised form is extremely difficult and time consuming with current HTML editors. More sophisticated packages that attempt to automate the process generally create poor quality markup. One solution is to take a middle road by developing macro suites that attempt to automate the markup process as much as possible while still retaining space for human intervention and decision in the most critical phases of markup. This approach ensures that clean markup is produced. In addition, when combined with SGML systems, this approach can significantly enhance the document production process.
For illustrative and experimental purposes, a set of free ICAAP macros for Microsoft Word 97 and above are provided to demonstrate the potential of information technology to reduce the time (and cost) required for journal production. For a complex document, these test macros can save literally hours of markup time. For illustrative purposes, the conversion of this article from its original to HTML and DHTML was timed. It took approximately 13 minutes to convert this article from Microsoft Word format to IXML format using the macros discussed in this paper. From the IXML format, special PERL filters were used to convert the IXML to the HTML and DHTML files you are now reading in just under 2 minutes. Of course, this estimate assumes that the article was submitted already in electronic format and thus did not require data entry. The estimate also assumes a correctly structured word-processor document with styles applied in a consistent manner to facilitate automation. The estimate of 14 minutes also does not include the time required to copy edit the article or the time required for final movement of the files to the server. It also does not include the handling of tables or math (an area of automation that I and ICAAP have yet to investigate). However it does include the sophisticated and intelligent handling of graphics and endnote text (note the pop-up graphic and endnotes in the DHTML version of this document - both the plain HTML and DHTML version were created simultaneously and instantly with ICAAP IXML filters).
It should be clear even from this informal experiment and production estimation that information technology can potentially lower the cost of tagging articles. Especially when considered against the minimal graphical, mathematical, and tabular requirements of many social science and humanities journals, this represents a significant point against the continued high cost of scholarly information - especially when this information is produced in online versions only. The application of word processor macros, and the use of intelligent SGML systems and filters, can reduce a complicated tagging an conversion process from a difficult and time consuming task to one that is simple and robust and that allows for the creation of multiple versions of documents from a single IXML (or SGML) source file. Even given the fact that the 14 minute production estimate for producing multiple versions of this article is idealised, the implications for the costing of electronic only scholarly journals should be evident.
© Copyright 1999 ICAAP.
IUICODE: 900.1999.2
Citation Format
Sosteric, Mike . (1999). ICAAP
Document Automation:
Standardising the Storage of Electronic Texts. The Craft
[iuicode: 900.1999.2]




** For a comprehensive review see http://homepage.interaccess.com/~cdavis/edit_rev.html
** See the SGML FAQ at http://www.isgmlug.org/whatsgml.htm for more information on SGML.
** A Document Type Definition specifies how tagging systems are to be applied to documents. For example, the HTML DTD specifies that all paragraphs are to be enclosed in a <P>.</P> element. HTML also specifies how quotations, lists, and other basic document structures are to be marked up.
** For more information see http://www.icaap.org/standards.html. For an example of the ICAAP DTD markup, see the IXML version of this article.
** Macros are sets of computer program statements that allow users to automate certain repetitive tasks. Over the years, the capabilities of word-processor macro languages have increased a hundred fold. Macro languages like that of Microsoft Word are now powerful enough to create computer viruses.
** However since the ICAAP IXML is designed to look like HTML, these macros can be used to automate regular HTML production.